以下主要來自 LLM Twin: Building Your Production-Ready AI Replica 課程內容
經過了前 10 天奠定了開發 GenAI 的基礎概念,下一步就正式進入系統設計的部份。
先整理了這次挑選的課程架構,我很喜歡這套課程是因為它完整的擴展了我過去的開發作品,不論是從設計面、或者是從功能面,所以只是看完第一堂課就決定要認真研讀了,只是遲遲沒有開始,剛好趁這次機會也好好整理過這門課程的內容。
先簡述這門課的目標,是開發 自己專屬的 LLM 分身。具體來說,就是將我們在 LinkedIn、Medium、GitHub 等社群平台上的貼文內容餵給 LLM,讓 LLM 了解並模仿我們的寫作風格,從而生成更符合個人風格的貼文。
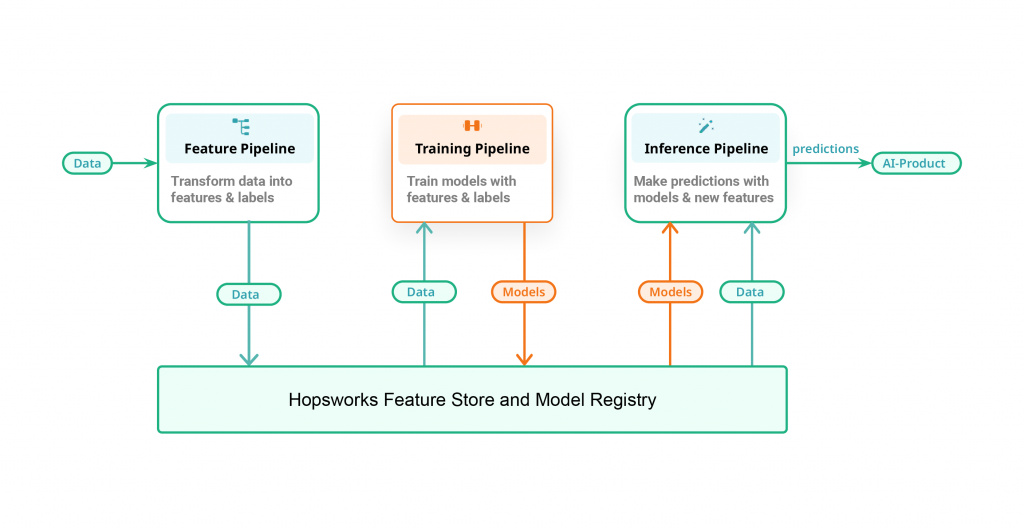
課程使用了 3-pipeline architecture 拆解架構,將機器學習組件分成特徵 (Features)、訓練 (Training) 和推理 (Inference) 三條 Pipeline,除了有明確的開發流程易於分工,清楚的架構和統一的儲存中心也有助於程式的建構和資源的控管。
具體來說,每條管道負責以下任務:
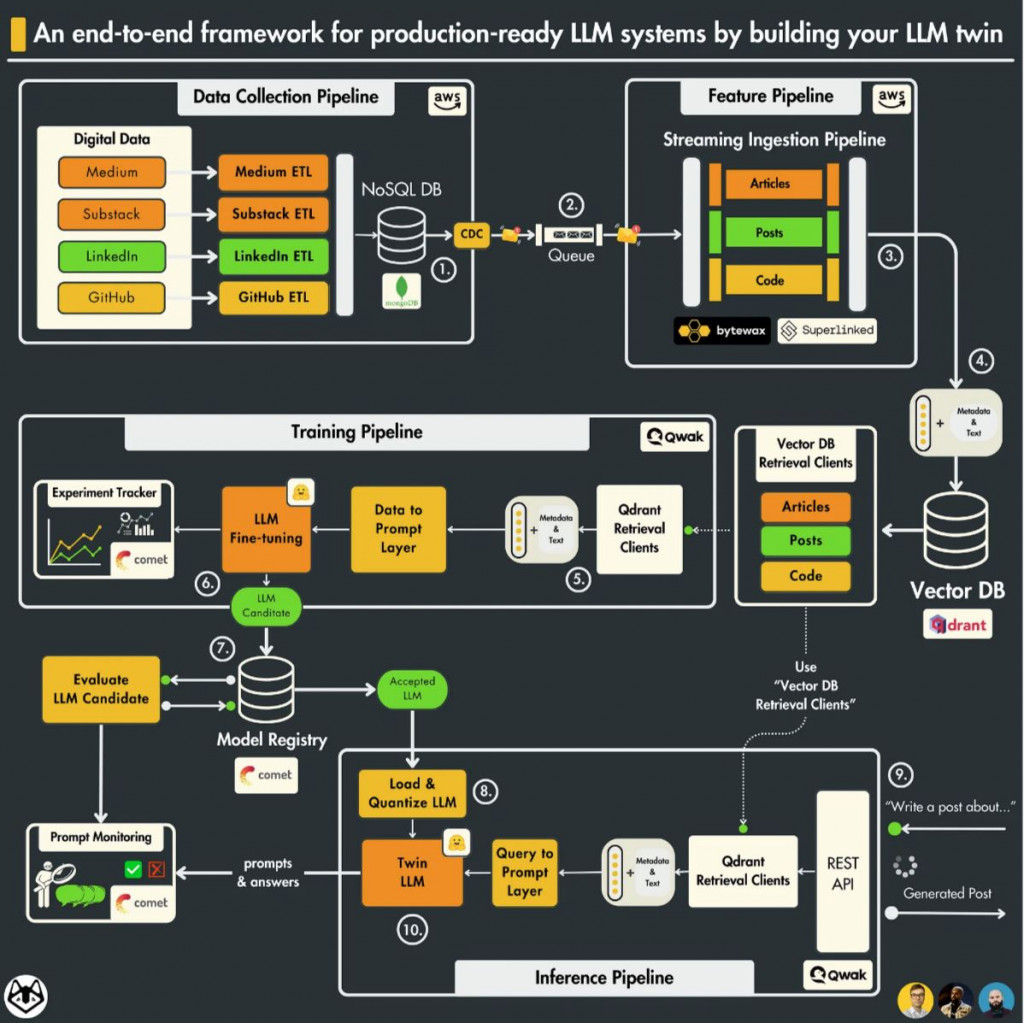
在第一堂課中,作者很仔細地說明了每一條 pipeline 的設計以及各個組件的選擇,增加了 data collection pipeline,完善了整個 MLOps 流程,接下來的寫作會依循官方提供的課程進度依序閱讀和梳理(以下是看圖猜出來的架構,會在閱讀中慢慢修正):
ref.


 iThome鐵人賽
iThome鐵人賽